
The robots.txt is discovered in 1994. Used to allow website owners to tell web search programs how to crawl your website. It works similarly to the Robots meta-label, which I recently explored in detail. The main difference is that the robots.txt document prevents web crawlers from seeing a page or tab. While the robots meta label only controls whether it is dropped. The robots.txt file is part of the robots exclusion protocol (REP)
The REP also includes directives like meta robot, as well as page-, subdirectory-, or site-wide instructions for how search engines should treat links (such as “follow” or “nofollow”).
By including a robots.txt document in the base of your website, you can prevent web crawlers from requesting sensitive records. For example, you can prevent a web searcher from crawling your image organizer. Or ordering a PDF document that is in a mysterious envelope.
Search Engine & robots.txt
Large companies will adhere to the policies you set. However, keep in mind that the policies you set in your robots.txt entry cannot be authorized. Crawlers for programs and helpless web search tools are unlikely to adhere to your policies and record anything they want. Fortunately, major web indexes adhere to the norm, including Google, Bing, Yandex, Ask, and Baidu.
In this article, I’ll explain the best way to create a robots.txt document and show you. Which records and registrations do you need to protect from search indexes for a WordPress website.
Check out the main rules of the robots exclusion standard.
You can generate robots.txt instantly. Just open a word processor and save a clear document as robots.txt. Once you have added some principles, save the document. And transfer it to the basis of your domain, for example, www.abc.com/robots.txt. Transfer the robots.txt to the base area.
WordPress plugin WP Robots Txt
I suggest that you include a 644 consent for the document. Most will set up this record with these consents after you transfer the document. You should also check out the WordPress module WP robots txt. Which allows you to easily customize the robots.txt document via the WordPress admin region. It saves you from having to re-transfer the robots.txt document via FTP when you change it.
Web indexes look for a robots.txt document at the base of your section when they crawl your site. If it’s not a big problem, note that a different robots.txt document should be created for each subdomain and different conventions like https://www.abc.com.
It doesn’t take long to fully understand the robots rejection standard because there are several rules to learn.
The two main mandates of the standard are:
- User-agent – Defines the web search tool to which a standard applies.
- Disallow – Instructs a search engine tool not to search and file a document, page, or catalog
Asterisk (*) is a wildcard with User-agent to refer to all web indexes. For example, you could add the following document to your robots.txt to prevent web indexes from crawling your entire site.
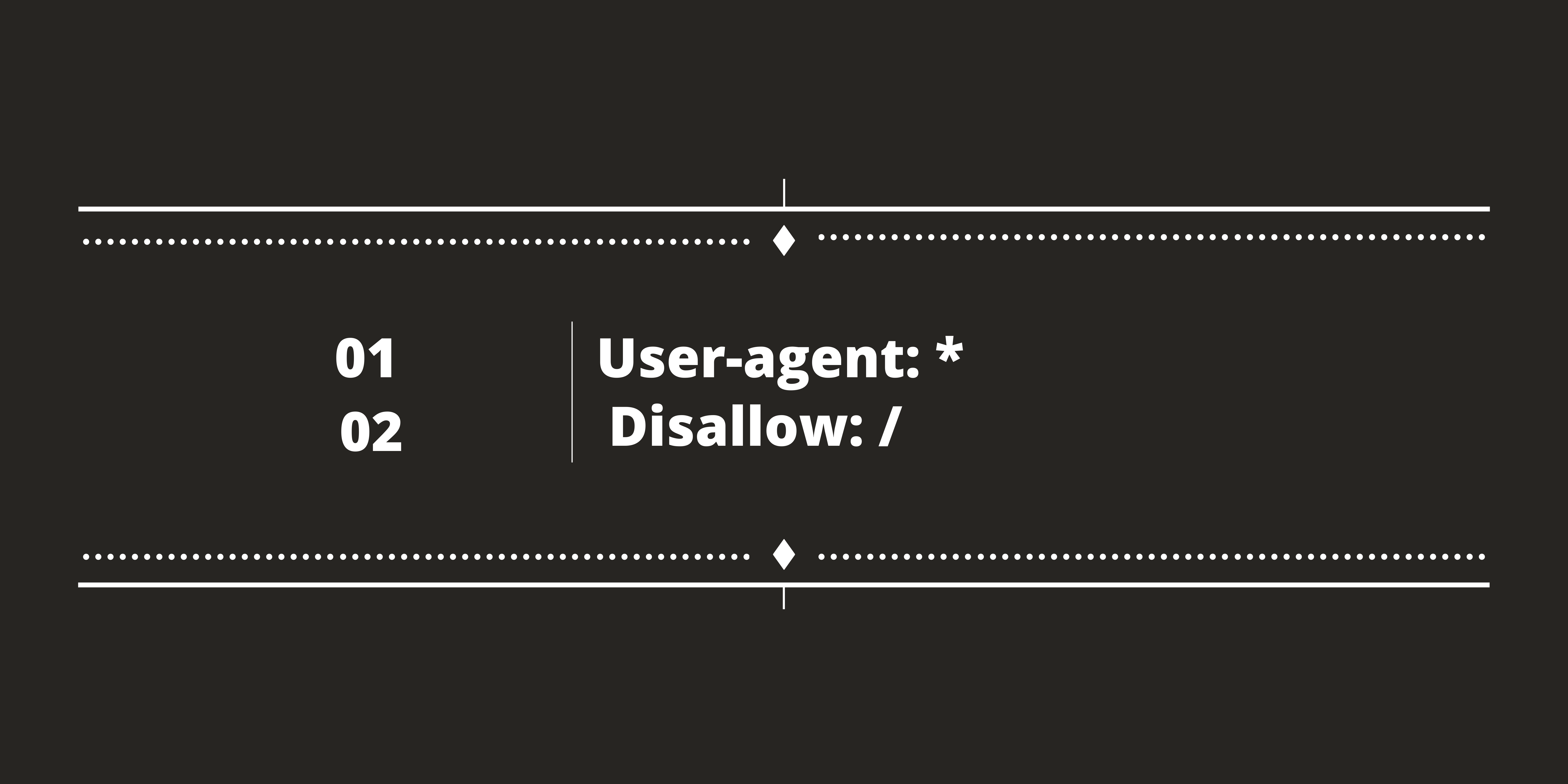
The above command is important in the event that you continue with another site. And don’t have to struggle with a web search instrument to rank your inadequate site.
Some websites use the ban command without forwarding slices to express that a site can be slid. This allows web indexes full access to your site.
The attached code expresses that all web indexes can slide your site. There is no reason to put this code alone in a robots.txt record because web indexes will crawl your site even if you do not include this code in your robots.txt document. at the end of a robots.txt document to point out the remaining client specialists.

Envelope Using Image
You can see in the model below that I have determined the image envelope using/image/ and not www.abc.com/image/. This is because robots.txt uses relative paths, not full URL paths. The slash (/) points to the base of space and thus applies rules to your entire site. Paths are very sensitive, so make sure you use the correct situation when tagging documents, pages, and catalogs.

Define Search Engine
To define mandates for explicit web indexes, you need to know the name of the Internet search bug (also known as the client specialist). Googlebot-Image, for example, will characterize rules for the Google Images crawler.
Note that if you specify explicit client specialists, list them at the beginning of your robots.txt document. User-agent: * at the end of the document to coordinate any user-agent that has not been clearly identified.
Generally, it is not the web indexes that search your site. For this reason, the term customer specialist, robot, or bot is regularly utilized rather than the term crawler. The number of web bots that could be cavorting on your website is enormous. The website Bots versus Browsers currently lists around 1.4 million client specialists in its dataset, and this number continues to increase every day. The list includes programs, gaming gadgets, working frameworks, bots, and the sky is the limit from there.
Bots versus Browsers is a helpful reference to check the intricacies of a client specialist you didn’t know about. You can also refer to User-Agents.org and User-Agent String. Fortunately, you don’t need to remember a considerable list of client specialists and crawlers of web search programs. You just need to know the names of the bots and crawlers you need to apply explicit principles to, and utilize the trump * to apply rules to all other things for all web search tools.
Below are some normal web search tool insects you may need to use:
- Bingbot – Bing
2. Googlebot – Google
3. Googlebot image – Google images
4. Googlebot news – Google news
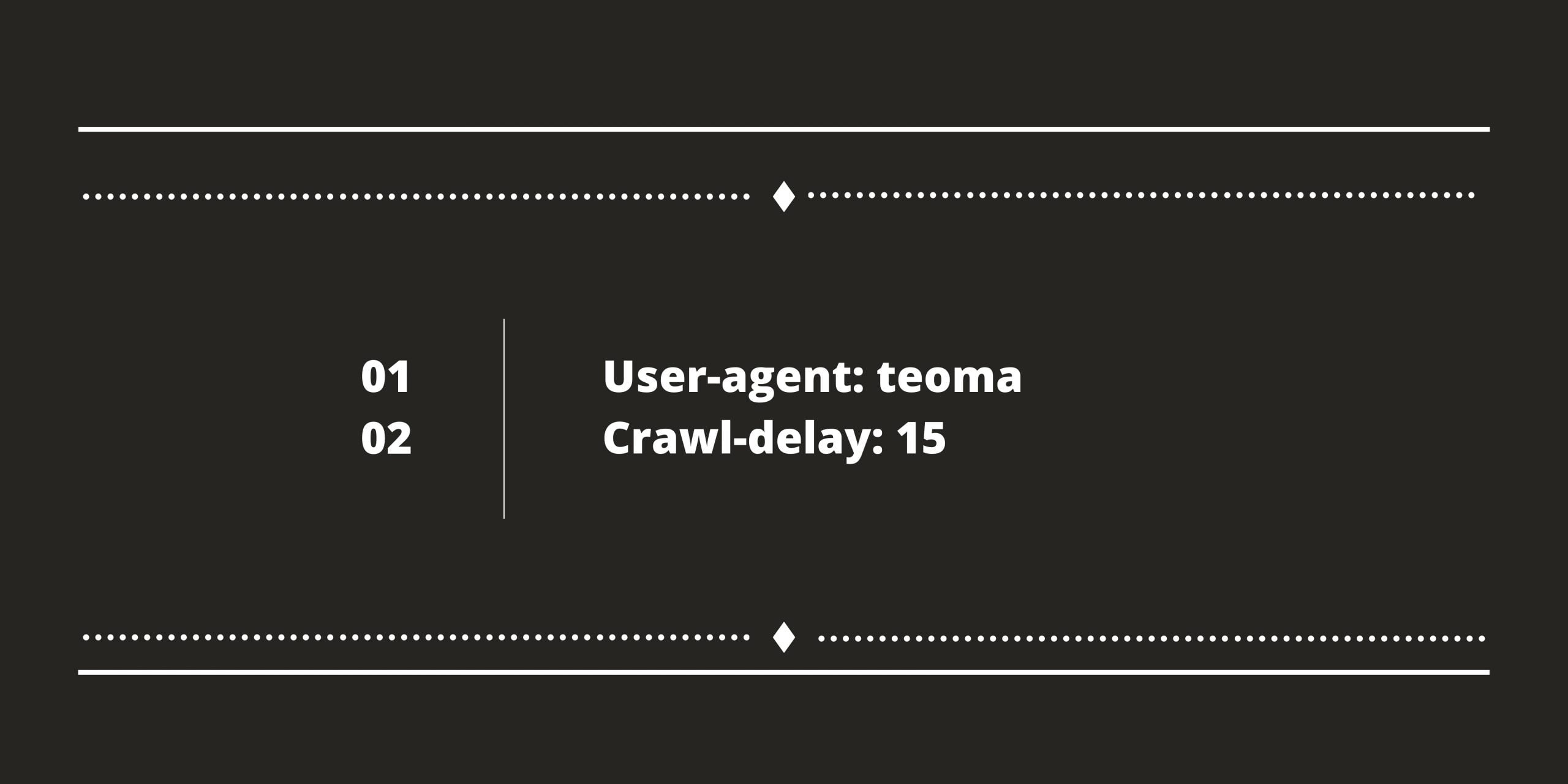
5. Teoma – Ask
Please note that Google Analytics does not display traffic from web index robots locally, as web crawler robots do not initiate Javascript. Google Analytics is set up to display data about web search robots crawling your site. Log record analyzers offered by most supporting organizations, like Webalizer and AWStats, show data about crawlers. I suggest checking these details for your website to find out how the web indexes work with your website content.

Note that Google doesn’t uphold the creep postpone order. To change the slither pace of Google’s insects, you need to sign in to Google Webmaster Tools and snap nearby Settings.
Google Webmaster Tools and click on Site Settings.
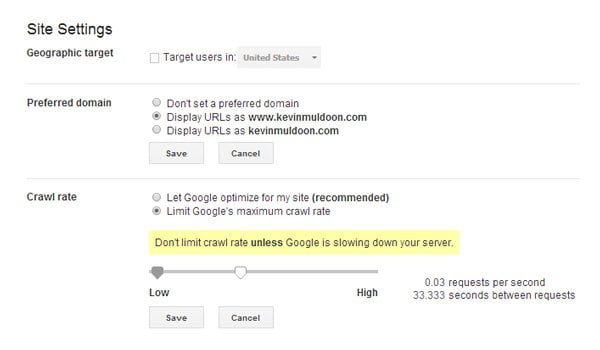
You can then change the creep delay from 500 seconds to 0.5 seconds. It is basically impossible to enter a worth straightforwardly; you need to pick the creep rate by sliding a selector. Moreover, it is basically impossible to set diverse creep rates for each Google insect. For instance, you can’t characterize one slither rate for Google Images and another for Google News. The rate you set is utilized for all Google crawlers.
A couple of web indexes, including Google and the Russian internet searcher Yandex, let you utilize the host order. This permits a site with different mirrors to characterize the favored area. This is especially helpful for enormous sites that have set up mirrors to deal with huge data transfer capacity necessities due to downloads and media.
I have never utilized the host mandate on a site myself, however, obviously, you need to put it at the lower part of your robots.txt record after the creep defers order. Make sure to do this in the event that you utilize the order in your site robots.txt record.
As should be obvious, the principles of the robots avoidance standard are straight forward. Know that if the standards you set out in your robots.txt record struggle with the guidelines you characterize utilizing a robots meta tag; the more prohibitive principle will be applied by the web crawler. This is something I talked about as of late in my post “How To Stop Search Engines From Indexing Specific Posts And Pages In WordPress”.





